




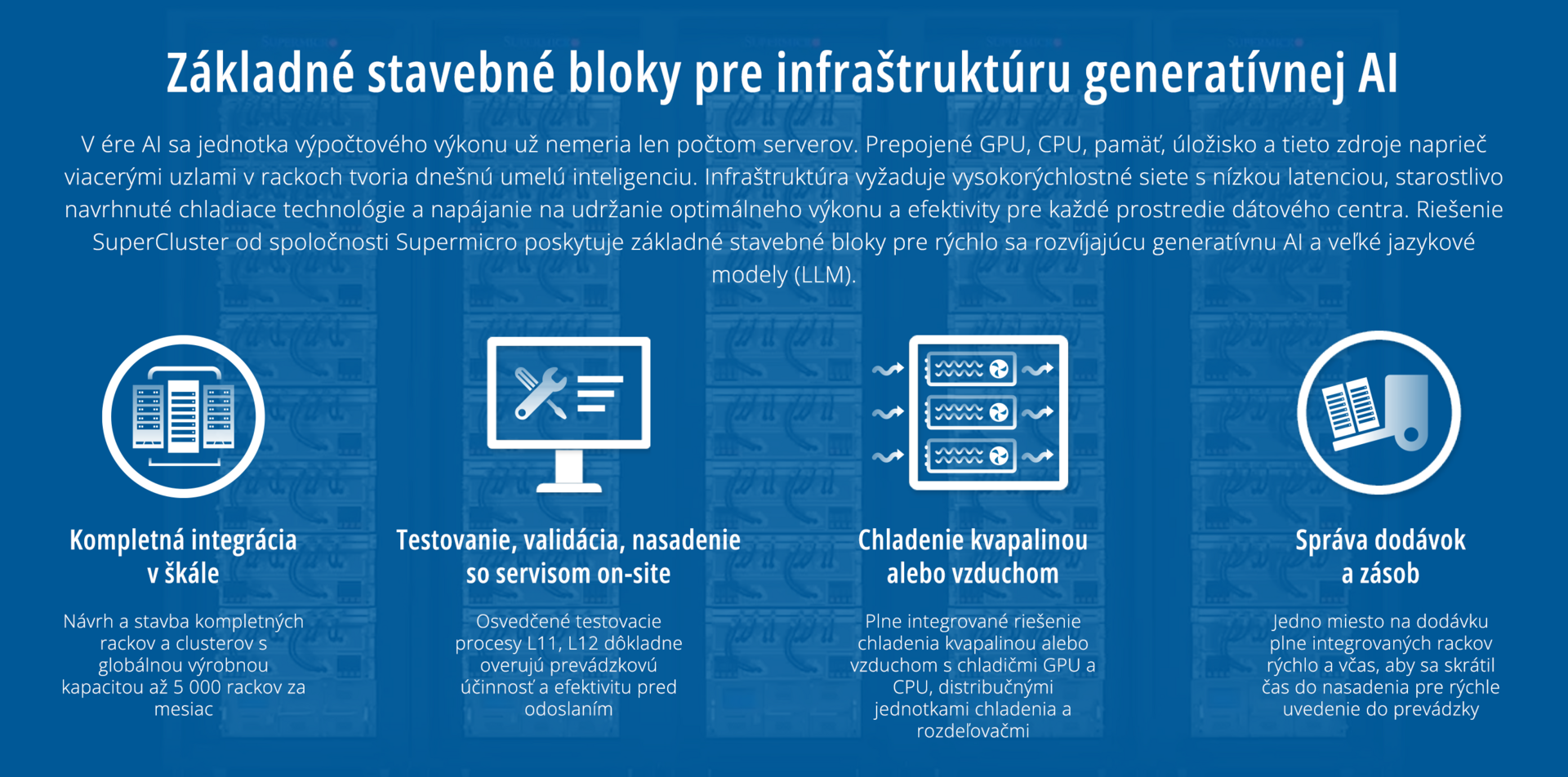
Komplexné riešenie dátového centra na kľúč urýchľuje dodávku pre kritické podnikové prípady a eliminuje zložitosť budovania veľkého klastra, čo predtým bolo možné len prostredníctvom intenzívneho ladenia návrhu a časovo náročnej optimalizácie superpočítačov.

 Najvyššia výpočtová hustota
Najvyššia výpočtová hustota

S 32 NVIDIA HGX H100/H200 8-GPU, 4U kapalinou chladených serverov (256 GPU) v 5 rackoch
- Zdvojnásobenie hustoty výpočtov pomocou vlastného riešenia kvapalinového chladenia Supermicro s až 40% úsporou nákladov na elektrinu pre dátové centrum
- 256 GPU NVIDIA H100/H200 v jednej škálovateľnej jednotke
- 20 TB HBM3 s H100 alebo 36 TB HBM3e s H200 v jednej škálovateľnej jednotke
- 1:1 networking ku každému GPU pre umožnenie NVIDIA GPUDirect RDMA a Storage pre trénovanie veľkých jazykových modelov s až triliónmi parametrami
- Prispôsobiteľná infraštruktúra úložiska pre dátové potrubie AI s poprednými možnosťami paralelného súborového systému
- Pripravené na softvér NVIDIA AI Enterprise
Preverený design

S 32 NVIDIA HGX H100/H200 8-GPU, 8U vzduchom chladených serverov (256 GPU) v 9 rackoch
- Osvedčená špičková architektúra pre nasadenie infraštruktúry AI vo veľkom meradle
- 256 GPU NVIDIA H100/H200 v jednej škálovateľnej jednotke
- 20 TB HBM3 s H100 alebo 36 TB HBM3e s H200 v jednej škálovateľnej jednotke
- 1:1 sieťovanie ku každému GPU pre umožnenie NVIDIA GPUDirect RDMA a Storage pre trénovanie veľkých jazykových modelov s až triliónmi parametrami
- Prispôsobiteľná infraštruktúra úložiska pre dátové potrubie AI s poprednými možnosťami paralelného súborového systému
- Pripravené na softvér NVIDIA AI Enterprise
 Inferencie v škále cloudu
Inferencie v škále cloudu

S 256 NVIDIA GH200 Grace Hopper Superčipy, 1U MGX servery v 9 rackoch
- Zjednotená pamäť GPU a CPU pre cloudové vysokoobjemové inferencie s nízkou latenciou a vysokou veľkosťou dávky
- 1U chladené vzduchom systémy NVIDIA MGX v 9 rackoch, 256 superčipov NVIDIA GH200 Grace Hopper v jednej škálovateľnej jednotke
- Až 144 GB HBM3e + 480 GB LPDDR5X, dostatok kapacity na umiestnenie modelu s viac ako 70B parametrami do jedného uzla
- Networking bez blokovania 400 Gb/s InfiniBand alebo Ethernet pripojené k sieťovej infraštruktúre typu spine-leaf
- Prispôsobiteľná infraštruktúra úložiska pre AI dátové pipeline s poprednými možnosťami paralelného súborového systému
- Pripravené na softvér NVIDIA AI Enterprise
Chcete sa dozvedieť viac?
Neváhajte sa obrátiť na náš obchodný tím, ktorý vám poskytne kompletné informácie a podporu.




